
Distinguished-Grade AI Accelerators for Data Engineering: What They Are and Where They Work Today
There is a growing narrative in the industry that AI has fundamentally changed data engineering. That LLMs can now build pipelines, convert legacy SQL, generate data models, design architectures, and modernize entire data estates with minimal human involvement. The demo videos look impressive. A prompt goes in, a Snowflake pipeline comes out. An architecture diagram materializes from a paragraph of requirements. Problem solved.
Except it is not solved. Not at enterprise scale. Not when you are building a new data platform from scratch and every modeling decision, pipeline pattern, and governance framework choice will compound for years. Not when the SQL estate has 12,000 undocumented stored procedures. Not when the original developers left five years ago and took the business logic with them. Not when the migration timeline is tied to a platform end-of-life deadline that the CFO is tracking on a weekly dashboard.
Whether you are building new or modernizing old, the challenges are real. This blog is a practitioner-level look at what "AI native data engineering" actually means today, where it genuinely helps, where it falls short, and how organizations should think about applying it without wasting time or budget on hype that does not deliver.
The Premise Everyone Gets Wrong
Most of the excitement around AI in data engineering is borrowed from the software development world. GitHub Copilot writes React components. Claude Code generates Python modules. Cursor builds full applications from natural language descriptions. The assumption is that the same approach transfers directly to data engineering.
It does not. And the reason is structural, not technical.
A software application and a data solution are fundamentally different things.
In software development, you start with a specification. You know what the application should do. The requirements may be incomplete, but you have a product owner, user stories, acceptance criteria, and a clear definition of "done." The code IS the product. You write it, test it, deploy it.
In data engineering, the landscape is entirely different. Consider just a few realities:
A data solution is not an application with predictable inputs and outputs. It is a system that must account for source system behavior you do not control, data quality issues you did not create, schema changes you were not warned about, and business logic that was encoded decades ago by people who are no longer available. The "specification" often does not exist. It must be extracted from the systems themselves.
Data design patterns are not application design patterns. A slowly changing dimension, a fact table grain decision, a late-arriving dimension handling strategy, a data vault hub-satellite relationship .. these are domain-specific architectural decisions that require deep understanding of both the business context and the target platform characteristics. An LLM that can write a REST API cannot automatically reason about whether your insurance claims data should be modeled as a transaction fact or an accumulating snapshot fact.
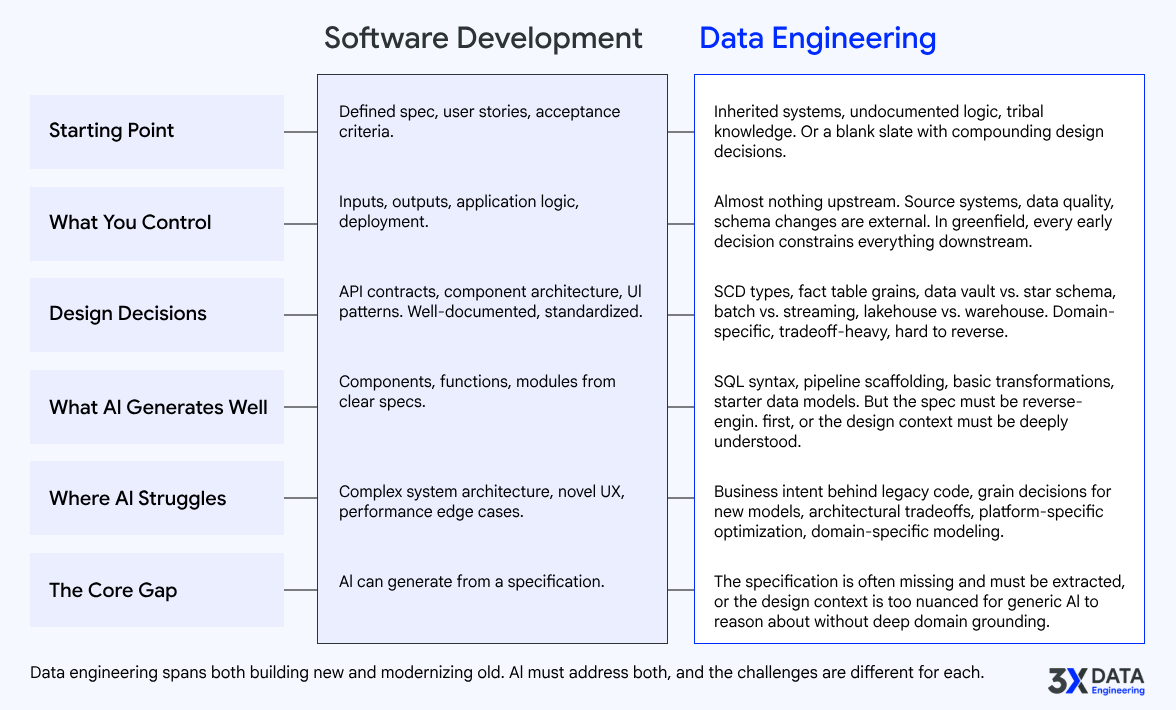
When you build a greenfield data platform, the decisions compound in ways that software development does not typically face. Choosing between a Snowflake dynamic table approach versus a dbt incremental model versus a Databricks Delta Live Table pipeline is not a syntax question. It is a decision that affects cost, latency, maintainability, team skill requirements, and long-term platform lock-in. These tradeoffs require architectural judgment that no current AI system can reliably provide without deep contextual grounding.
And when you are modernizing an existing data estate, the challenge is even harder. You are not building from a spec. You are reverse-engineering intent from code that may be thousands of lines long, spread across multiple systems, with implicit dependencies that only become visible when something breaks. This is not a code generation problem. It is a system understanding problem.
The point is not that AI has no role here. It does, and it is a meaningful one. The point is that applying AI to data engineering requires understanding what makes data engineering different from software development. Treating them as the same problem leads to failed pilots, unrealistic expectations, and wasted investment.
The Data Engineering Lifecycle: Why It Is Harder to Accelerate Than You Think
Before we can talk about where AI helps, we need to be honest about the data engineering lifecycle as it actually plays out in enterprise programs. Not the clean five-stage diagram from the textbook. The real version, with all its friction.
Discovery and System Understanding
Every data engineering initiative, whether greenfield or modernization, starts with understanding. What systems exist? What data do they hold? How does it flow? What does it mean? Who depends on it?
In practice, this phase alone can consume 20 to 30 percent of total program effort. Enterprise data estates are sprawling. A typical Fortune 500 company operates hundreds of source systems, thousands of SQL objects, and tens of thousands of data assets spread across on-premises databases, cloud warehouses, ETL tools, flat files, APIs, and spreadsheets that somehow became critical infrastructure.
Most of this is poorly documented. The documentation that does exist is often outdated, incomplete, or misleading. The people who built the original systems have frequently moved on. What remains is code, metadata, and tribal knowledge locked in the heads of a shrinking pool of legacy subject matter experts.
Assessment, Planning, and Estimation
This is where most enterprise data programs lose months before a single line of migration or development code is written.
Building a defensible modernization roadmap requires answering questions like: How many objects need to be migrated? What is the complexity distribution? What are the dependencies between objects? What is the conversion difficulty for each source-target platform pair? How should the work be sequenced to minimize risk? What is the realistic effort and timeline?
In most organizations, these questions are answered through a painful combination of manual code review, stakeholder interviews, spreadsheet-based estimation, and educated guessing. T-shirt sizing is the norm. Analogies from past projects (which may not be comparable) serve as the basis for multi-million-dollar budget requests.
There is no widely adopted, fact-based methodology for data engineering estimation. Unlike software development, where story points and velocity tracking have at least some standardization, data engineering projects are estimated through a mix of experience, intuition, and hope. The result is that most modernization programs exceed their original budget and timeline estimates, often significantly.
This is not because teams are incompetent. It is because the problem is genuinely hard. A single stored procedure can range from a trivial SELECT statement to a 2,000-line procedural monster with dynamic SQL, cursor operations, error handling, and embedded business rules. Treating them as equivalent during planning guarantees inaccurate estimates.
Architecture and Design
Whether greenfield or brownfield, architecture decisions set the trajectory for everything downstream. Platform selection, data modeling approach, pipeline orchestration strategy, governance model, security framework, cost optimization approach .. each of these requires specialized expertise.
In greenfield scenarios, teams need to make foundational choices: lakehouse versus warehouse, medallion architecture versus data vault, batch versus streaming versus hybrid, single-platform versus multi-platform. Each choice creates constraints and opportunities that are difficult to reverse later.
In brownfield modernization, the architecture challenge is even more nuanced. You must design a target state that accommodates the existing business logic, data volumes, SLA requirements, and team capabilities while also modernizing patterns and reducing technical debt. This is not a template exercise. It requires deep understanding of both the source and target ecosystems.
Engineering, Conversion, and Pipeline Development
This stage covers two distinct but often overlapping workstreams. In modernization programs, it means converting thousands of SQL scripts, ETL jobs, and data pipelines from legacy platforms to modern ones. In greenfield programs, it means building new data models, writing new pipeline code, and implementing new platform patterns from scratch. Most enterprise programs involve both simultaneously.
For conversion, the work is tedious, repetitive, and error-prone when done manually. It is the most obvious candidate for automation. But enterprise SQL estates are not uniform collections of clean, well-structured queries. They contain proprietary functions, platform-specific optimizations, implicit type conversions, dialect-specific syntax, error handling patterns, and performance tuning hints that do not translate directly between platforms.
For new development, the challenge is different but equally time-consuming. Building a dimensional model for a new analytics domain requires understanding business requirements, source system structures, grain decisions, and slowly changing dimension strategies. Writing production-grade pipeline code means handling error scenarios, implementing idempotency, managing schema evolution, and following platform-specific best practices. Each new pipeline is a design exercise, not just a coding exercise.
Testing and Validation
Testing data pipelines is fundamentally different from testing software applications. In modernization, you are verifying that data transformations produce the same business outcomes across source and target platforms, often with different data types, precision levels, and null handling behaviors. In greenfield development, you are validating that newly built models and pipelines correctly implement business requirements, handle edge cases, and perform at expected volumes. In both cases, the challenge is not just technical correctness but business correctness, and the definition of "correct" varies by domain, by use case, and sometimes by stakeholder.
Deployment and Operationalization
Getting code to production is only half the challenge. Operating data pipelines at enterprise scale requires monitoring, alerting, incident response, SLA management, cost optimization, and capacity planning. These are organizational and operational concerns, not code generation problems.
The point of walking through this lifecycle is to make one thing clear: data engineering is a multi-dimensional discipline. It is not just about writing code. It is about understanding systems, making architectural decisions, planning programs, managing risk, and operating complex infrastructure. AI that helps with one dimension but ignores the others provides limited value.
Where AI Actually Helps Today: An Honest, Stage-by-Stage Assessment
Now the useful part. Where does AI genuinely deliver value in the data engineering lifecycle today, and where does it fall short?
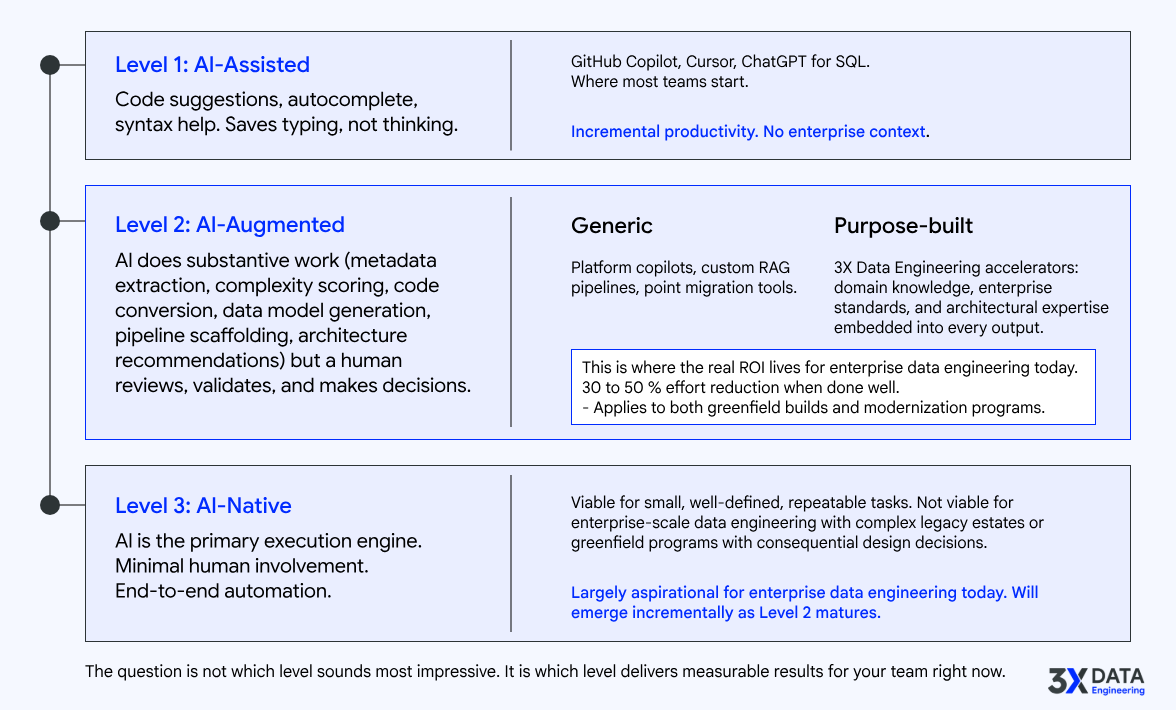
The critical insight is this: the value of AI in data engineering scales directly with the quality and depth of domain knowledge embedded into the AI workflow. A generic LLM given a SQL file will produce generic output. An LLM combined with well-structured data engineering domain knowledge, platform-specific patterns, enterprise standards, and architectural context produces dramatically better results.
This is not a subtle difference. It is the difference between output that looks right and output that IS right.
Discovery and System Understanding
AI capability today: LLMs are strong at structured parsing. They can read SQL, extract table and column references, identify join conditions, map basic data lineage, and generate documentation from code. When combined with systematic metadata extraction frameworks that feed the right context (database catalogs, schema definitions, object dependencies, execution logs), the results improve significantly.
Where it falls short: Dynamic SQL (where the query text is constructed at runtime), EXEC statements, cross-database and cross-server references, and business logic embedded deep in procedural code. An LLM can parse the syntax of a CASE statement with 47 WHEN clauses. It cannot tell you that those 47 conditions represent a premium adjustment algorithm that was negotiated with regulators in 2019 and must be preserved exactly as-is during migration. That requires domain context that no model has.
The practical verdict: AI-augmented discovery, where AI does the heavy structural lifting and human experts interpret meaning and validate accuracy, delivers 30 to 50 percent effort reduction compared to fully manual approaches. This is real, measurable, and available today. But it requires a well-designed framework that feeds the right context to the AI, not just raw SQL files.
Assessment and Planning
AI capability today: Automated complexity scoring is genuinely powerful. AI can classify thousands of SQL objects by conversion difficulty (simple DDL, standard DML, complex procedural logic, dynamic SQL, platform-specific extensions), map dependency graphs, identify high-risk objects, and generate data-driven effort estimates that are more defensible than spreadsheet-based guessing.
Where it falls short: Estimating organizational overhead like team ramp-up time, stakeholder alignment, testing cycles, environment provisioning, and governance reviews. AI can tell you that converting 3,000 Teradata stored procedures to Snowflake will require approximately X engineering-hours based on complexity distribution. It cannot tell you that your enterprise change management process will add 40 percent overhead to every deployment cycle.
The practical verdict: AI-powered assessment produces SI-grade modernization roadmaps and effort estimates in days rather than weeks. The output is grounded in actual system analysis, not assumptions. This is one of the highest-ROI applications of AI in the entire data engineering lifecycle.
Architecture and Design
AI capability today: Can suggest patterns, generate starter data models, recommend platform features, and validate designs against best practices. When grounded in architect-grade knowledge bases that encode real-world tradeoffs and platform-specific guidance, the output quality improves substantially.
Where it falls short: Architecture is judgment, not pattern matching. Deciding whether to use Snowflake dynamic tables or dbt incremental models depends on cost sensitivity, team SQL proficiency, latency requirements, existing tooling investments, and long-term platform strategy. These are contextual decisions that require understanding the organization, not just the technology.
The practical verdict: AI as an architecture copilot that augments human architects with on-demand pattern recommendations, design validation, and best-practice enforcement. Not AI as a replacement for architectural thinking.
Engineering, Conversion, and Pipeline Development
AI capability today: This is where AI has made the most visible progress, across both conversion and new development. For conversion, LLMs can translate between SQL dialects, transform ETL logic, and produce platform-specific code with genuinely high accuracy for standard patterns. For new development, AI can generate data models from requirements descriptions, produce pipeline scaffolding aligned to target platform patterns (Snowflake tasks, Databricks DLT, dbt models), and create boilerplate code for common patterns like incremental loads, SCD implementations, and data quality checks. When grounded in platform-specific standards and enterprise coding conventions, the output quality for both conversion and generation improves substantially.
Where it falls short: For conversion, the "long tail" of enterprise SQL remains challenging: proprietary functions, vendor-specific extensions, implicit platform behaviors (how Teradata handles QUALIFY versus how Snowflake handles it), and complex procedural logic with deep nesting and error handling. A converted procedure that compiles is not the same as one that produces correct results under all edge cases. For new development, AI-generated data models and pipeline code look structurally sound but often miss domain-specific nuances: grain decisions that depend on how the business actually uses the data, performance optimizations that depend on real data volumes and query patterns, and error handling strategies that depend on the SLA and business impact of each pipeline. Generated code is a strong starting point, not a finished product.
The practical verdict: For conversion, AI handles 60 to 70 percent of typical enterprise objects effectively within a proper framework. The remaining 30 to 40 percent requires expert engineering. For new development, AI accelerates the scaffolding and boilerplate dramatically, allowing engineers to focus on the design decisions, business logic, and optimization that require human judgment. In both cases, the combined approach (AI for the volume and structure, experts for the judgment and edge cases) is significantly faster than either approach alone.
Testing, Validation, Deployment, and Operations
AI can generate test scaffolding, comparison queries, and monitoring configurations. These are useful accelerators. But test strategy design, result interpretation, operational planning, and SLA management remain human-driven activities that depend on business context and organizational knowledge.
Existing Ways to Leverage AI for Data Engineering Acceleration
Today, most teams approach AI for data engineering through a few common paths:
General-purpose AI coding assistants
like GitHub Copilot, Cursor, or Claude Code. These are helpful for writing SQL, Python, and pipeline code faster. They reduce boilerplate and accelerate syntax-level work. But they have no awareness of your enterprise standards, target platform conventions, data modeling patterns, or organizational context. They are general-purpose tools applied to a specialized domain.
Platform-native AI features
like Databricks Assistant, Snowflake Copilot, or BigQuery Duet AI. These are more context-aware within their respective platforms but limited to that single ecosystem. They help with query optimization and basic code suggestions within the platform, but they do not address the broader lifecycle challenges of discovery, assessment, cross-platform migration, or architecture.
Custom prompt engineering and RAG pipelines
that teams build internally to ground LLMs in their own code, documentation, and standards. These can be effective but require significant engineering investment to build, maintain, and keep current. Most organizations do not have the AI engineering expertise to build production-grade RAG systems alongside their data engineering workload.
Point migration tools
from vendors like Ispirer, AWS Schema Conversion Tool, or SSMA. These handle specific source-to-target conversion paths with rule-based engines increasingly augmented by AI. They are effective for their specific scope but do not provide lifecycle-wide acceleration.
Each of these approaches addresses a piece of the problem. None of them address the full data engineering lifecycle holistically.
This is where purpose-built data engineering accelerators make a fundamentally different impact. At 3X Data Engineering, we have built a portfolio of enterprise-grade accelerators that go beyond generic AI assistance by embedding deep data engineering domain knowledge, Distinguished-grade architectural expertise, and advanced intelligence mechanisms into purpose-built engines.
Our accelerators are not wrappers around LLMs. They are frameworks that combine structured domain knowledge (data modeling standards, platform-specific best practices, migration patterns, greenfield architecture principles, complexity classification models) with AI capabilities to produce actionable, industry-standard deliverables: SI-grade modernization roadmaps, greenfield architecture strategies, architect-grade data models, production-ready pipeline code, comprehensive system documentation, and defensible effort estimates.
The difference is the knowledge layer. A generic AI tool asked to generate a data model produces a generic schema. Our Distinguished Architect Grade Data Modeling Generator, informed by enterprise modeling standards, platform-specific conventions, and industry best practices, produces standards-compliant conceptual, logical, and physical models that pass architecture review. A generic AI tool given a SQL file produces a generic conversion. Our Enterprise Bulk Code Conversion Factory, informed by platform-specific conversion rules, enterprise coding standards, and quality validation checkpoints, produces code that aligns with your target platform best practices.
Similarly, our Fact-Based Modernization Roadmap and Effort Estimator does not just count SQL objects. It classifies them by real conversion complexity, maps their dependencies, scores them against platform-specific difficulty matrices, and generates phased migration plans with defensible timelines. And our Distinguished Greenfield Architecture Strategizer does not just suggest a platform. It produces first-principles architecture designs optimized for your data volumes, scalability requirements, cost constraints, and long-term evolution path.
Our accelerators address the most common challenges across the entire data engineering lifecycle, whether you are building new or modernizing existing systems: understanding legacy systems (Distinguished Legacy Systems Intelligence Engine), extracting and managing metadata at scale (Enterprise Metadata Intelligence Engine), reverse-engineering undocumented code (Intelligent Reverse Engineering Engine), generating standards-compliant data models for new and modernized platforms (Distinguished Architect Grade Data Modeling Generator), producing production-ready pipeline code for any target platform (Distinguished Engineer Grade Data Pipeline Code Generation Engine), planning greenfield programs from first principles (Distinguished Greenfield Architecture Strategizer), designing phased modernization strategies for complex brownfield environments (Distinguished Brownfield Modernization Strategizer), and converting legacy SQL and ETL estates at scale (Enterprise Bulk Code Conversion Factory).
Each of these accelerators produces deliverables that enterprise teams can immediately act on, not suggestions that require additional engineering to become useful.
How 3X Data Engineering Helps You Leverage the Latest AI Innovations
The AI landscape for data engineering is evolving rapidly. Reasoning models like Claude with extended thinking, OpenAI o3, and Gemini 2.5 Pro represent a genuine step change in what AI can handle. These models can hold significantly more context, reason through multi-step logic, and handle more complex SQL patterns than earlier generations.
What this means practically: for conversion workloads, the percentage of enterprise SQL objects that can be accurately converted without human intervention has grown from roughly 40 percent (with earlier LLMs) to 60 to 70 percent with current reasoning models. Multi-CTE queries, nested conditional logic, and moderately complex stored procedures are now within reach. For new development, AI can generate increasingly sophisticated data models, pipeline code, and platform-specific implementations when given proper architectural context. The quality of AI-generated new code has improved to the point where it serves as a strong, review-ready starting point rather than a rough draft that needs substantial rework. Both improvements change the economics of data engineering acceleration.
But here is what reasoning models do NOT solve: they do not understand your business domain. They do not know your enterprise standards. They do not have context about your regulatory requirements, your team's platform proficiency, or your organization's risk tolerance. They cannot make the judgment calls that distinguish a technically correct output from a strategically sound one, whether that output is a converted stored procedure or a newly generated data model.
3X Data Engineering bridges this gap. Our team combines 25+ years of hands-on enterprise data engineering experience with deep AI engineering expertise. We do not just deploy LLMs against your SQL files or hand them a requirements document. We build and continuously refine accelerators that embed the domain context, architectural patterns, and quality standards that make AI outputs enterprise-ready, whether those outputs are converted legacy code, newly generated data models, pipeline implementations, or architecture strategies.
When new model capabilities emerge, we integrate them into our accelerator framework. When reasoning models improved context handling, we expanded our code conversion engine to handle larger, more complex procedural objects in single passes and enhanced our data modeling generator to produce richer, more nuanced models. When structured output capabilities matured, we enhanced our metadata extraction to produce richer, more standardized documentation and improved our architecture strategizers to generate more detailed, actionable recommendations.
This is the advantage of working with a team that lives at the intersection of AI engineering and enterprise data engineering. We track the model frontier so our clients do not have to. The improvements flow directly into the accelerators, and our clients see better results with each iteration.
We also bring something that no AI model provides: accountability. When our Fact-Based Modernization Roadmap says a migration will require X effort over Y months, that estimate is backed by real system analysis and our team's experience delivering Fortune 10-scale programs. It is not a probabilistic guess from an LLM. It is a professional assessment grounded in data and expertise.
Who Should Explore AI Native Data Engineering
Based on the enterprise challenges we see repeatedly, here is a practical guide to readiness:
You are a strong candidate if:
You are managing a large legacy data estate with hundreds to thousands of SQL scripts, ETL jobs, or data pipeline assets that need modernization, migration, or documentation. The sheer volume makes manual approaches impractical within your timeline and budget.
You are building a new data platform on Snowflake, Databricks, BigQuery, or Fabric and need to accelerate architecture design, data modeling, pipeline development, and platform strategy without spending months in design committees before a single pipeline goes live.
You are planning or actively executing a migration to a modern platform and need to accelerate assessment, conversion, and validation across a large object inventory.
Your project estimates, whether for greenfield builds or modernization programs, keep missing the mark because they are based on analogies and assumptions rather than actual complexity analysis. You need defensible, fact-based roadmaps and effort estimates that stakeholders and finance teams can trust.
Your legacy subject matter experts are retiring or leaving, and you are facing a knowledge cliff where critical system understanding walks out the door. You need to capture and codify that knowledge before it is gone.
You are under pressure from AI initiatives to make your data estate "AI-ready" but your foundational data engineering (metadata, lineage, quality, governance) is not where it needs to be. You need to modernize the foundation before building AI applications on top of it.
You operate in a regulated or security-sensitive environment (financial services, insurance, healthcare) and need sovereign or on-premises AI deployment options that keep your data within your infrastructure.
Your data engineering team is strong but stretched thin. You need to multiply their effectiveness, not replace them. You want tools that augment your senior architects and engineers, giving them leverage across larger estates without scaling headcount linearly.
You should hold off if:
You expect AI to handle end-to-end migration with no expert oversight. It cannot. Not reliably. Not at enterprise scale.
You have no access to the source systems or source code. AI cannot reverse-engineer what it cannot see.
Your team lacks the data engineering fundamentals to evaluate whether AI-generated output is correct. AI accelerates expert work. It does not replace the need for expertise.
Why There Is No Single Solution to All Your Data Engineering Problems
This is worth stating directly because the market is full of vendors claiming otherwise.
No single tool, platform, or accelerator solves every data engineering challenge. The lifecycle is too broad, the problems too varied, and the organizational contexts too different.
A metadata intelligence engine, no matter how sophisticated, does not build your target architecture. A code conversion factory, no matter how accurate, does not tell you which objects to migrate first or which ones to retire. A data modeling generator does not define your governance framework or your testing strategy.
Enterprise data engineering requires a portfolio approach: different accelerators and capabilities applied to different stages of the lifecycle, coordinated by experienced architects who understand how the pieces fit together.
This is why 3X Data Engineering built a focused portfolio of purpose-built accelerators rather than a single monolithic platform. Each accelerator addresses a specific, high-impact challenge in the data engineering lifecycle. And when the standard accelerators do not cover a client's unique situation, we rapidly design and build custom accelerators tailored to their specific platforms, data domains, and operational constraints.
The goal is not to sell you a single product. It is to equip your team with the right combination of tools, intelligence, and expertise to move faster and with more confidence across your specific data engineering challenges.
The Bottom Line
AI native data engineering, as a fully autonomous discipline, does not exist today for enterprise-scale work. And chasing that vision prematurely leads to failed pilots, wasted budgets, and eroded trust in AI's real capabilities.
AI-augmented data engineering, on the other hand, is real, measurable, and delivering results today. Teams that are applying it well are seeing 30 to 50 percent reductions in manual effort across discovery, assessment, architecture, engineering, conversion, and documentation stages. That is not a marginal improvement. Whether you are building a new data platform or modernizing a legacy estate, that translates to months of compressed timeline and significant cost savings.
But the ROI is not automatic. It depends on applying AI to the right stages, with the right domain context, and with the right expert oversight.
Before you invest, figure out where the ROI is clearest for your organization:
If your biggest bottleneck is understanding what you have, start with AI-powered discovery and metadata intelligence. Measure how much time your team currently spends on manual system analysis and documentation. That is your baseline.
If your biggest bottleneck is planning and estimation, whether for a greenfield build or a modernization program, start with automated complexity assessment and fact-based roadmapping. Compare the accuracy and speed against your current spreadsheet-driven approach.
If your biggest bottleneck is engineering volume, whether building new data models and pipelines or converting legacy objects at scale, start with a proof of value on a representative workload. Measure output quality, human review effort, and total cycle time against your fully manual approach.
If your biggest bottleneck is architecture and strategy, start with AI-augmented architecture design that gives your architects an informed starting point backed by enterprise best practices. Measure how much faster your team moves from requirements to a defensible architecture with accelerator support.
If your biggest bottleneck is scaling expertise, start with accelerators that embed architectural and engineering best practices into your team's workflows. Measure whether junior engineers can produce senior-grade output with accelerator support.
Pick the area with the clearest pain, run a focused proof of value, and measure the results. Then expand based on evidence, not promises.
3X Data Engineering helps organizations become AI native data teams one step at a time.
We do not pitch a future vision of fully autonomous data engineering. We deliver practical, enterprise-grade accelerators that make your existing data engineering teams dramatically more productive today. We start with your actual challenges, whether that is understanding 10,000 undocumented SQL scripts, building a defensible modernization roadmap, converting a massive ETL estate to a modern platform, or launching a new data program with architect-grade foundations.
Our approach is grounded in 25+ years of hands-on enterprise data engineering experience, embedded directly into accelerators that your team can use immediately. We combine deep data engineering domain knowledge with advanced AI capabilities to produce deliverables that meet enterprise standards, not prototypes that need additional engineering to become useful.
We augment and empower your teams. We do not create dependency. With our source ownership model, your team can operate, maintain, and enhance the accelerators independently.
If you want to see what AI-augmented data engineering looks like against your actual data estate, we run proof-of-value engagements that deliver measurable results within weeks, not months.
The industry will get to AI native data engineering eventually. The organizations that get there first will be the ones that started with practical, well-grounded acceleration today, learned what works in their context, and built their AI-native capabilities incrementally based on evidence.
That is how real transformation happens. One step at a time, grounded in facts, driven by engineering discipline.
3X Data Engineering is an enterprise data engineering acceleration company that helps organizations understand, modernize, and scale complex data estates using Distinguished-grade AI accelerators. Learn more at 3xdataengineering.com

