Teradata to Fabric Migration: Why BTEQ Scripts Are the Real Bottleneck
Introduction
Your Teradata environment has been the backbone of enterprise analytics for a decade or more. Thousands of BTEQ scripts run nightly batch cycles. Hundreds of macros encode business rules that nobody documented. FastLoad and MultiLoad utilities move terabytes through a PE/AMP architecture that your team understands intuitively. Now leadership wants all of this in Microsoft Fabric.
The business case is clear: Teradata licensing costs are unsustainable, cloud-native analytics offer better economics, and Fabric consolidates compute, storage, and reporting into a single platform. What is not clear is how long this Teradata to Fabric migration will actually take, because most teams discover the real complexity only after the project starts.
What Makes Teradata to Fabric Migration Fundamentally Different
Synapse to Fabric is a migration within the Microsoft ecosystem. SQL Server to Fabric shares a T-SQL dialect. Teradata to Fabric is neither. It is a migration between two platforms that share almost nothing: different SQL dialects, different architectures, different data loading paradigms, different scripting languages. Every stored procedure, every BTEQ script, every FastLoad job needs to be rewritten, not adapted.
Teradata estates also tend to be large and mature. Organizations that invested in Teradata did so because they had serious data volumes and complex analytical workloads. A mid-size Teradata environment typically contains 1,000 to 5,000 database objects, hundreds of BTEQ scripts encoding ETL logic and operational workflows, and dozens of FastLoad and MultiLoad jobs handling bulk data movement. Larger enterprises run 10,000+ objects with decades of accumulated business logic.
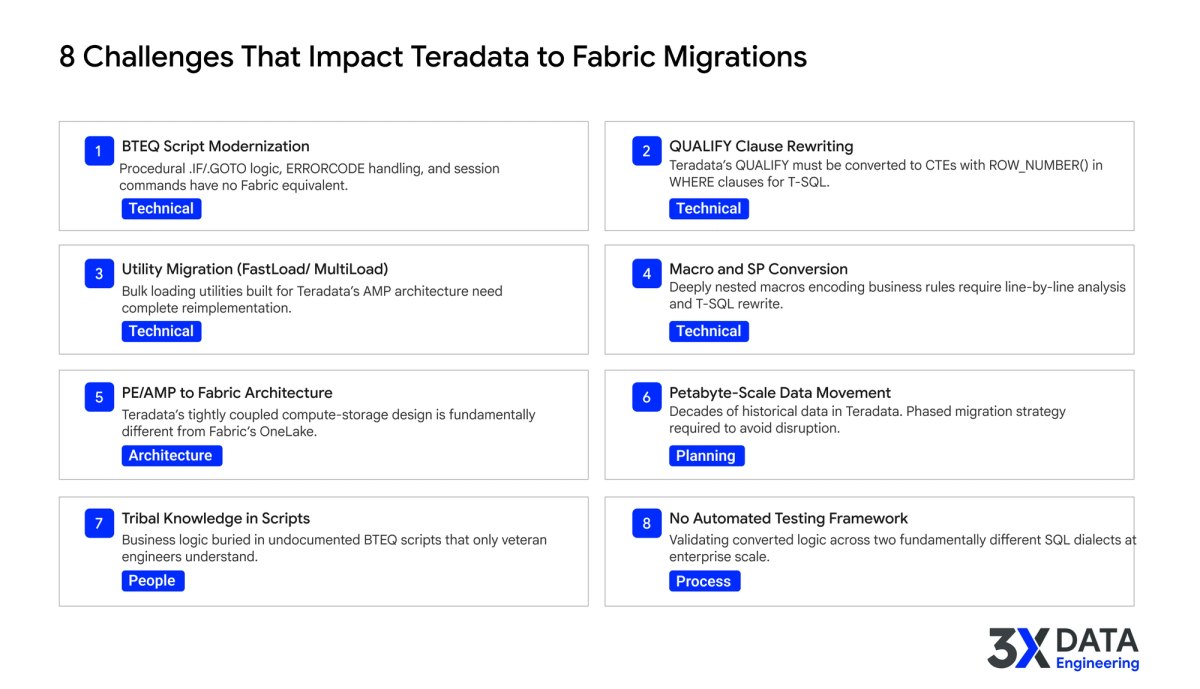
Eight Teradata-Specific Challenges That Derail Fabric Migrations
Teams that have migrated within the Microsoft ecosystem are often surprised by how different a Teradata migration is. The challenges span architecture, planning, people, and process.
1. BTEQ Script Modernization
BTEQ (Basic Teradata Query) is Teradata's command-line scripting tool, and it is deeply embedded in most Teradata estates. BTEQ scripts are not just SQL wrappers. They contain procedural logic using .IF/.GOTO branching, ERRORCODE and ACTIVITYCOUNT-based flow control, session management commands like .LOGON/.LOGOFF, and file I/O operations. None of these constructs have equivalents in Fabric.
Converting BTEQ scripts requires understanding the intent of each script, then rebuilding that logic using T-SQL stored procedures, Spark notebooks, or Fabric pipeline activities. A single complex BTEQ script with nested .IF conditions and error handling can take a senior engineer several days to convert and test. Multiply that by hundreds of scripts, and the conversion effort alone can consume a year.
2. QUALIFY Clause Rewriting
Teradata's QUALIFY clause allows filtering on the result of a window function directly in the query. It is elegant, compact, and used extensively throughout Teradata SQL. Fabric's T-SQL does not support QUALIFY. Every query that uses it needs to be rewritten as a CTE with the window function in the SELECT list and the filter applied in a WHERE clause on the outer query.
This is a mechanical transformation, but at scale it compounds. A Teradata estate with 500 stored procedures and views might contain QUALIFY in 30 to 40% of them. Each rewrite needs to preserve the original logic and be tested against the source results.
3. FastLoad, MultiLoad, and TPump Migration
Teradata's bulk loading utilities were designed specifically for its PE/AMP architecture. FastLoad handles high-speed initial loads into empty tables. MultiLoad manages upserts and deletes against populated tables. TPump handles near-real-time continuous loading. These are not generic SQL operations. They use Teradata-specific protocols, session management, and error handling that have no parallel in Fabric.
Migrating this data loading infrastructure means rebuilding it entirely using Fabric Data Factory pipelines, Spark notebooks, or COPY INTO commands. The logic is not complex, but the volume of individual load jobs in a mature Teradata estate makes this a significant effort.
4. Macro and Stored Procedure Conversion
Teradata macros are a unique construct that bundles multiple SQL statements into a single callable object. Many Teradata estates use macros extensively for encapsulating business rules, multi-step transformations, and parameterized operations. Some macros call other macros, creating nested chains that are difficult to trace without dedicated tooling.
Stored procedures in Teradata use a different procedural language than Fabric's T-SQL. Variable declarations, cursor handling, error trapping, and dynamic SQL all follow Teradata-specific syntax. Each procedure needs line-by-line analysis and rewrite.
5. PE/AMP to Fabric Architecture Redesign
Teradata's architecture is fundamentally different from Fabric's. Teradata uses Parsing Engines (PEs) and Access Module Processors (AMPs) in a tightly coupled shared-nothing design where data distribution across AMPs determines query performance. Fabric uses a cloud-native architecture with OneLake as a unified storage layer and independent compute nodes.
This is not a configuration change. It is a complete architecture redesign. Table distribution strategies, join optimization approaches, and workload management patterns that your team has refined over years do not translate. The target architecture needs to be designed from Fabric's capabilities, not from the source system's patterns.
6. Petabyte-Scale Data Movement
Teradata estates often contain 10 to 20+ years of historical data. Moving petabytes of data from an on-premises Teradata system to Fabric's OneLake requires careful planning around network bandwidth, data extraction parallelism, and phased migration waves. A full data extract from a large Teradata system can take weeks even with optimized network throughput.
Teams need a phased migration strategy that moves data in priority order, validates each wave against the source, and maintains dual-system operations during the transition period.
7. Tribal Knowledge in Undocumented Scripts
Teradata environments accumulate institutional knowledge in ways that are difficult to extract. BTEQ scripts written by engineers who left years ago contain business rules that nobody else fully understands. Macro chains encode transformation logic that was never documented outside the code itself. Comments are sparse, naming conventions are inconsistent, and the only people who truly understood the full picture have moved on.
This is not unique to Teradata, but the depth of the problem is often worse because Teradata environments tend to be older and more mature. A 15-year-old BTEQ script running a critical nightly batch may be the only record of a specific business calculation.
8. No Cross-Dialect Testing Strategy
Validating that converted code produces the same results across two fundamentally different SQL dialects is harder than it sounds. Teradata SQL and Fabric T-SQL handle NULL propagation, date arithmetic, string comparisons, and rounding differently. These edge cases do not show up in basic testing. They surface in production when a financial report produces a different total or a customer segmentation query returns a different count.
Most teams do not have a structured approach for cross-dialect validation at scale. Without automated validation that compares results across both platforms, discrepancies accumulate silently.

Where AI Acceleration Changes the Teradata Migration Equation
The reason Teradata to Fabric migrations take 18 to 30 months manually is not that each individual task is impossible. It is that the volume of conversion work overwhelms even large engineering teams, and the cross-dialect gap between Teradata SQL and Fabric T-SQL means nothing carries over automatically.
What makes AI acceleration different is what it encodes. The 3X MigrateTo Fabric Accelerator is infused with Distinguished-level architect experience, the kind of deep, cross-platform knowledge that takes a decade of enterprise data engineering to build. It performs a comprehensive deep dive into the source Teradata estate and produces architect-quality artifacts at scale.
Automated Estate Discovery
The accelerator connects directly to Teradata Vantage and inventories everything: tables, stored procedures, macros, views, BTEQ scripts, FastLoad/MultiLoad jobs, and cross-object dependencies. It captures the full estate, including the objects that only exist because someone built them five years ago and nobody removed them.
Outcome: Complete estate visibility in days instead of 6 to 10 weeks of manual cataloging. The full inventory surfaces objects and dependencies that manual discovery typically misses.
Object-Level Complexity Scoring
Every object gets analyzed individually: lines of code, Teradata-specific construct usage (QUALIFY, SET tables, BTEQ control flow), dependency depth, and conversion difficulty. Each object receives a complexity tier: standard (AI converts automatically), complex (engineer reviews AI output), or architect-required (human decision needed).
Outcome: Defensible effort estimates per object, replacing the "average time per BTEQ script" assumption that builds 40 to 60% error into every Teradata migration plan.
Dependency and Lineage Mapping
The deep dive traces dependencies across macros, stored procedures, views, and BTEQ scripts automatically. Macro chains that call other macros get fully unwound. The result is a complete lineage from source ingestion through transformation to downstream consumption.
Outcome: A migration sequence plan that prevents "we migrated this table but the macro that populates it is still in Teradata" scenarios.
Target Architecture Recommendations
The accelerator evaluates the source estate against Fabric's capabilities and generates architecture recommendations: which objects map to Warehouse (T-SQL, Gold layer), which map to Lakehouse (Spark, Bronze/Silver layers), how to segment domains across Fabric workspaces, and where the medallion architecture applies. These recommendations reflect Distinguished-level architect judgment informed by the actual objects and data volumes.
Outcome: Architecture decisions grounded in data and senior-level platform expertise, made in days instead of weeks of workshops.
Automated BTEQ and Code Conversion
BTEQ scripts are parsed, the intent of each script is analyzed, and the logic is converted to Fabric-native patterns: T-SQL stored procedures for data transformations, Spark notebooks for complex ETL, and pipeline activities for orchestration. Teradata-specific SQL constructs (QUALIFY, SAMPLE, SET tables, Teradata date functions) are converted to T-SQL equivalents. The accelerator handles 70 to 80% of conversions automatically and routes the remaining 20 to 30% to engineers with specific context on what needs human judgment.
Outcome: The BTEQ conversion bottleneck compresses from 6 to 14 months of manual work to 3 to 6 weeks of AI-accelerated conversion plus engineer review.
Utility and Pipeline Translation
FastLoad, MultiLoad, and TPump jobs are analyzed for their data movement patterns and rebuilt as Fabric Data Factory pipelines and COPY INTO operations. The accelerator maps source-to-target data flows, handles the protocol translation, and generates pipeline definitions that engineers validate rather than build from scratch.
Outcome: Data loading infrastructure migrated in weeks instead of months. Engineers focus on validating pipeline behavior, not rebuilding hundreds of load jobs manually.
Sprint Planning and Effort Estimation
Object-level complexity scores roll up into a total effort estimate broken down by tier. The accelerator generates a sprint-by-sprint migration plan with resource allocation mapped to actual complexity. Program managers get a roadmap built on system facts, not assumptions.
Outcome: A Teradata migration timeline that leadership can trust because every number ties back to an analyzed object and a measured complexity score.
Automated Testing and Validation
The accelerator generates cross-dialect validation scripts that compare Teradata SQL output against Fabric T-SQL output for every converted object. Row counts, data values, aggregation results, and edge-case behaviors are validated systematically rather than spot-checked manually.
Outcome: Comprehensive testing coverage that catches subtle cross-dialect differences before they reach production.
The pattern across all capabilities is consistent: work that consumed senior engineers for months gets compressed to days and weeks, with output quality reflecting Distinguished-level architect expertise applied at scale.
That is how an 18-month Teradata migration becomes 10 to 14 weeks. Not by adding headcount. By changing what the headcount does.
Learn how 3X Data Engineering's MigrateTo Fabric Accelerator automates BTEQ conversion, complexity scoring, and architecture design for Teradata estates.
How 3X Data Engineering Approaches Teradata to Fabric Migration
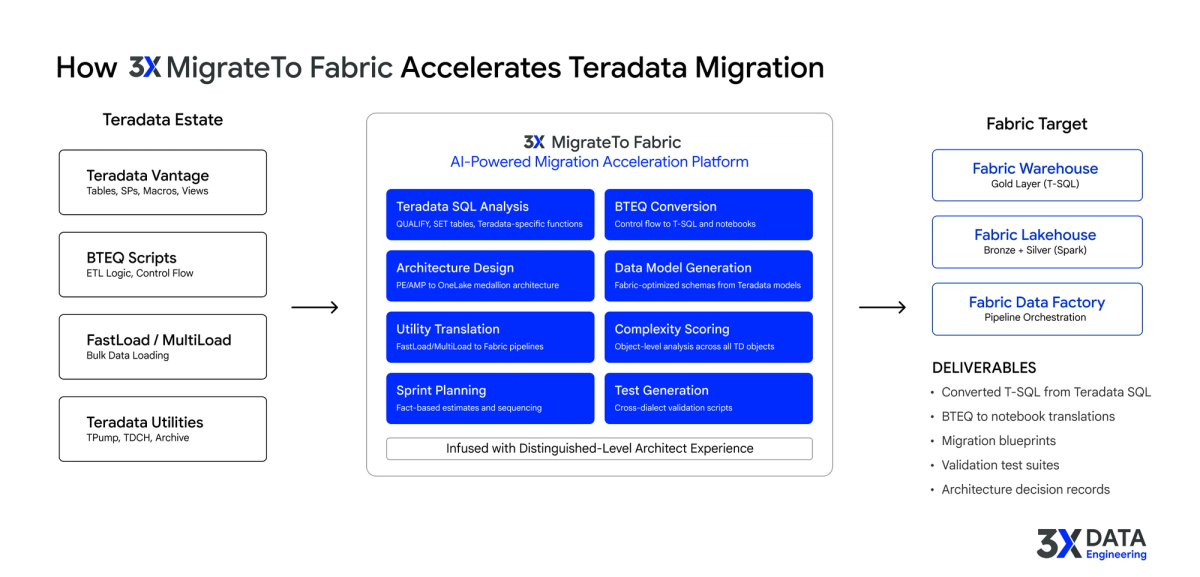
3X Data Engineering built the MigrateTo Fabric Accelerator for exactly this class of problem: large, complex source estates where the volume of conversion work makes manual migration timelines measured in years. The accelerator connects directly to Teradata Vantage, extracts the complete estate inventory including BTEQ scripts and utility jobs, and runs AI-powered complexity scoring on every object.
The output is not a rough assessment. It is an object-level migration blueprint with complexity tiers, effort projections, architecture recommendations for the Fabric target, and a sprint-by-sprint migration plan. For the conversion step, it produces Fabric-native T-SQL, Spark notebooks, and pipeline definitions.
The assessment phase that typically takes 3 to 6 months compresses to days. The full migration that traditionally spans 18 to 30 months compresses to 10 to 14 weeks. The engineers still own every critical decision. The accelerator handles the volume.
Looking Ahead
Teradata has served enterprise analytics well, but the economics and the architecture have shifted. The organizations moving to Fabric now are the ones that will have modern, cost-effective analytics platforms while competitors are still converting BTEQ scripts. The question is not whether to migrate. It is whether to do it in 18 months or 14 weeks.
If your team is evaluating a Teradata to Fabric migration, 3X Data Engineering's Acceleration Advisory delivers a fact-based migration roadmap in days, not months.

