AI-Powered Legacy Code Modernization: From Months of Conversion to Weeks
Introduction
Every data engineering team that has attempted a large-scale migration knows this moment. The assessment is done, the target platform is selected, the architecture is approved. Then someone runs the numbers on code conversion. 4,200 SQL scripts. 600 stored procedures. 350 ETL jobs. All need to be rewritten, most of them into PySpark. The timeline estimate comes back: 14 months of manual engineering. That is the moment the program stalls.
Legacy code conversion is the single largest time sink in enterprise data modernization. Not because the work is intellectually hard, but because it is voluminous, pattern-based, and relentlessly manual. And the conversion itself is not where programs go wrong. Programs fail earlier, when teams commit to a timeline without truly understanding what their legacy code does. The quality of your code inventory, complexity scoring, and conversion planning determines everything downstream: the conversion path, the effort estimate, the team structure, and ultimately whether the program delivers on time.
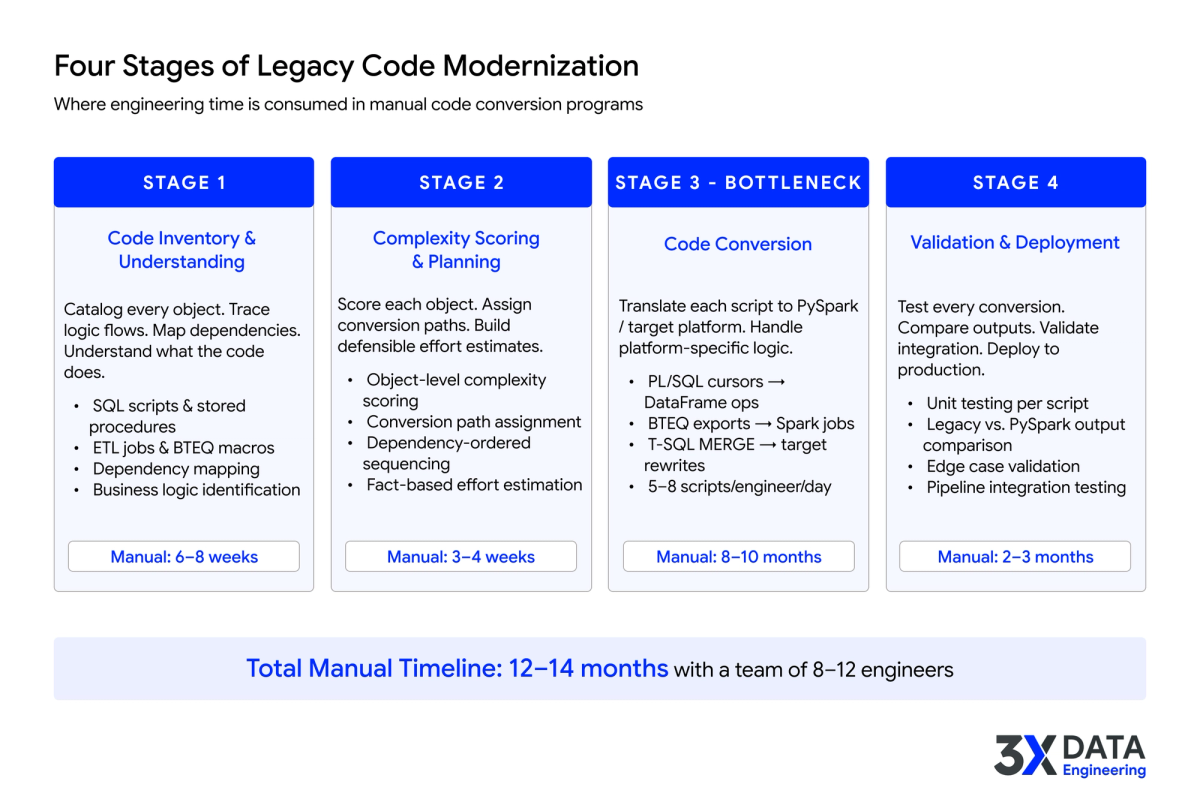
Four Stages of Legacy Code Modernization
Whether done manually or with AI, legacy code modernization follows four stages. Where time is spent at each stage is what separates programs that deliver on time from ones that miss by months.
1. Code inventory and understanding
Before converting a single line of code, teams need to understand what they have. This means inventorying every SQL script, stored procedure, ETL job, BTEQ macro, and legacy codebase object. But inventory is just the surface. The real work is understanding what the code does: tracing logic flows end to end, mapping dependencies across procedures, functions, views, and tables, and identifying business rules embedded in code that nobody documented.
In enterprise environments, this is the hardest step. Oracle PL/SQL packages with 15 years of accumulated logic, Teradata BTEQ scripts with undocumented dependencies, SQL Server stored procedures calling linked servers across three environments. The original developers are gone. Tribal knowledge sits with a handful of senior engineers. Teams that skip this step, or do it superficially, discover the gaps mid-conversion when rework is most expensive.
Manually, this phase consumes 6-8 weeks of senior engineer time. It is the foundation everything else depends on.
2. Complexity scoring for better planning and effort estimation
Not all code objects are equal. A 30-line SQL view is a fundamentally different conversion challenge than a 2,000-line stored procedure with dynamic SQL, nested cursors, and platform-specific constructs like Oracle's CONNECT BY or Teradata's QUALIFY clause.
Complexity scoring evaluates each object based on factors that actually affect conversion difficulty: dependency depth, use of platform-specific features, dynamic SQL patterns, business logic density, and transformation complexity. This scoring determines the conversion path for every object. Simple objects (typically 70-80% of most codebases) follow standard transformation patterns. Medium-complexity objects need conversion with engineer review. High-complexity objects require senior engineers to make architectural decisions about how the logic should be restructured for PySpark.
More importantly, complexity scoring produces defensible effort estimates. When your estimate accounts for each object's real complexity rather than rough per-script multipliers, the roadmap becomes reliable. Without it, teams either over-engineer simple conversions or underestimate complex ones. Both blow up timelines.
Why Modernization Timelines Slip The Six Root Causes
For a deeper look at why assumption-based estimation derails programs, see our analysis of the six root causes behind modernization timeline slippage.
Read more : https://www.3xdataengineering.com/
3. Code conversion
This is where most of the engineering hours accumulate in a manual approach. An engineer picks up a legacy SQL script, reads the logic, understands the intent, translates it to PySpark, and handles platform-specific differences: Oracle cursor loops becoming DataFrame operations, Teradata BTEQ exports becoming structured Spark jobs, SQL Server MERGE statements requiring restructuring.
For straightforward scripts, this takes hours. For complex stored procedures with dynamic SQL and embedded business logic, it takes days per object. Multiply across thousands of objects and even a team of 10 experienced engineers converting 5-8 scripts per day needs 10-14 months to work through a typical enterprise codebase. The volume overwhelms any staffing plan.
4. Validation and deployment
Every converted script needs testing. Does the PySpark output produce the same results as the legacy SQL? Do edge cases (nulls, empty sets, date boundaries) behave consistently? Manual testing at this scale creates a second bottleneck, and conversion errors discovered during testing require rework cycles.
Even after individual scripts pass, they need to work together. Pipeline orchestration, scheduling dependencies, error handling, and monitoring all need to be rebuilt for the target platform. This final stage surfaces integration issues that were invisible during isolated script conversion.
How AI Accelerators Compress Each Stage
AI-powered code conversion does not skip any of these four stages. What changes is how long each one takes and how much manual effort it requires.
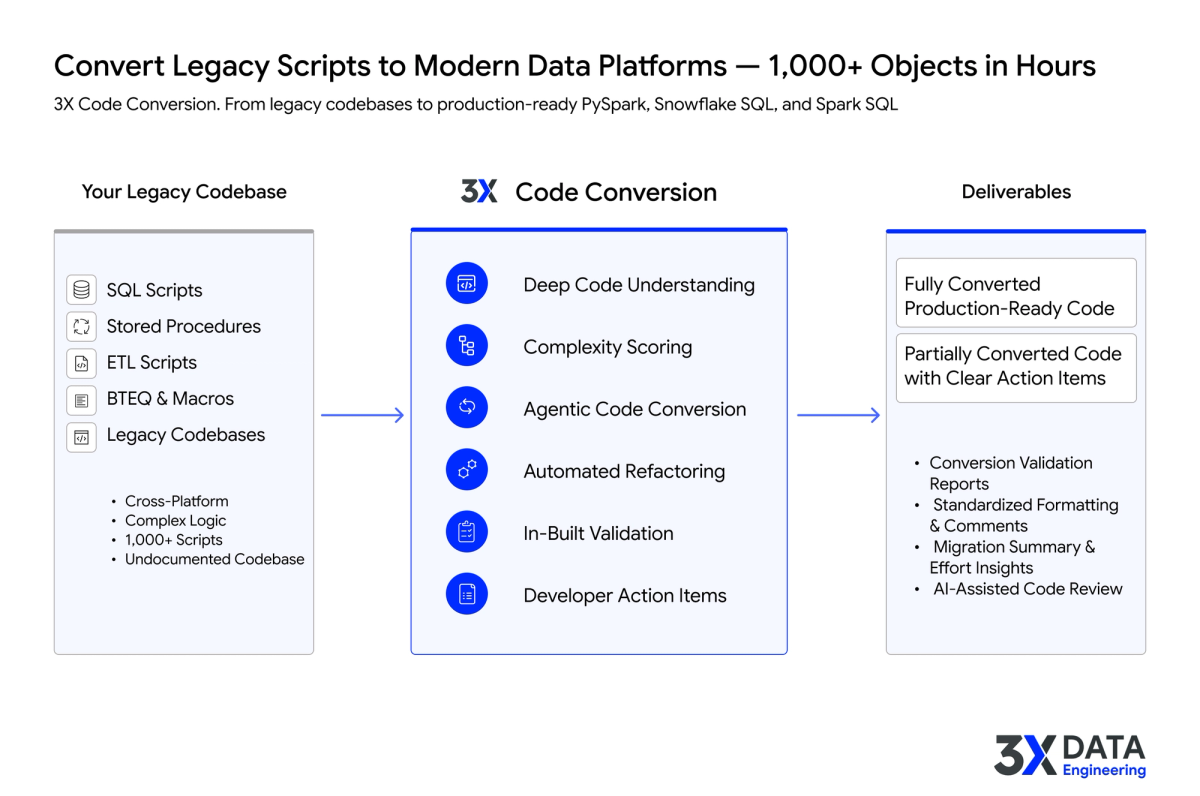
Deep code understanding and automated inventory
Instead of engineers manually tracing stored procedure logic across 1,000+ objects, accelerators ingest the entire legacy estate: SQL scripts, stored procedures, ETL jobs, BTEQ macros, all of it. They trace dependencies, map logic flows, and produce documentation that captures what the code actually does, not just what someone remembers it doing. The inventory phase that takes senior engineers 6-8 weeks completes in days.
AI-powered complexity scoring and conversion planning
Rather than manually triaging thousands of objects, the accelerator scores each one based on what actually affects conversion difficulty: dependency chains, platform-specific constructs, dynamic SQL patterns, business logic density. Each object gets assigned to the right conversion path, and the effort estimate is grounded in real analysis rather than rough multipliers. Program managers get a defensible roadmap in hours rather than weeks.
Agentic code conversion with automated refactoring
Purpose-built code conversion accelerators do not just translate syntax. They understand the semantic intent of the code and generate equivalent PySpark (or Snowflake SQL, Spark SQL, or other modern targets) that preserves business logic using native target platform patterns. Oracle PL/SQL cursor loops become PySpark DataFrame transformations. Teradata BTEQ exports become structured Spark jobs. SQL Server T-SQL becomes properly abstracted for the target environment.
The output is two-tiered: fully converted production-ready code for the pattern-based majority, and partially converted code with clear developer action items for the objects that need human judgment. Standardized formatting and comments are applied across the entire converted codebase, so engineers reviewing the output work with clean, consistent code rather than inconsistent manual translations.
3XDE Code Conversion Accelerator
Learn how the 3XDE Code Conversion Accelerator handles bulk legacy-to-PySpark conversion with deep code understanding, complexity scoring, and agentic conversion.
Explore the Accelerator : https://www.3xdataengineering.com/accelerators/code-conversion
In-built validation and AI-assisted code review
Validation reports ship alongside the converted code: input/output comparisons, edge case coverage, regression tests that verify PySpark results against legacy output. AI-assisted code review flags potential issues and provides confidence scores. Testing stops being the second bottleneck and becomes a parallel process that runs alongside conversion.
The Real Timeline Comparison

For a typical enterprise codebase (3,000-5,000 SQL objects, 500+ stored procedures, multiple ETL frameworks), the difference is stark:
Manual conversion: 12-14 months, team of 8-12 engineers, effort estimation based on assumptions, inconsistent code quality across engineers, testing as a sequential bottleneck.
AI-accelerated conversion: 8-12 weeks, smaller team focused on review and edge cases, effort estimation grounded in complexity scoring, standardized output with validation reports, fully converted production-ready code plus clearly flagged items requiring human attention.
The 60% reduction in manual effort redirects engineers from syntax translation to the work that genuinely requires their expertise: validating business logic, handling edge cases, optimizing PySpark performance, and ensuring pipeline integration.
How 3X Data Engineering Approaches This
3X Data Engineering's Code Conversion Accelerator was built for exactly this problem: enterprise codebases with thousands of objects, multiple legacy platforms, and a timeline that does not forgive guesswork. It covers all four stages, from code inventory and understanding through complexity scoring, conversion to PySpark (or Snowflake SQL, Spark SQL, and other modern targets), and validation with clear developer action items for anything that needs human judgment.
What engineers receive is not a pile of raw translations. It is production-ready code for the pattern-based majority, partially converted code with clear action items for complex objects, and validation reports that show exactly where human attention is needed. Formatting and comments are standardized across the entire codebase, so review time drops and consistency goes up.
Get a Fact-Based Conversion Roadmap
If your team is facing a large-scale code conversion, 3XDE's Acceleration Advisory provides a fact-based assessment of your codebase and a defensible conversion roadmap grounded in real complexity analysis.
Talk to 3XDE Advisory : https://www.3xdataengineering.com/advisory
Looking Ahead
The enterprises that complete their legacy code modernization on time will not be the ones with the largest engineering teams. They will be the ones that invested in understanding their codebase first, used AI-powered complexity scoring to plan defensible conversion paths and effort estimates, and applied AI acceleration to the pattern-based work so their best engineers could focus on the judgment calls that matter. The technology exists today. The question is whether your program builds on a foundation of deep code understanding and fact-based planning, or on assumptions.

