The Three Categories of Data Engineering Work: What Needs Human Judgment, What to Accelerate, and What to Automate
Introduction
Most data engineering leaders treat automation as a binary question: either you automate something or you do it manually. This framing is the root cause of two expensive mistakes. Teams that automate too aggressively end up with brittle pipelines and AI-generated code that nobody trusts. Teams that automate too cautiously end up with senior engineers spending 70% of their time on work that follows recognizable patterns, work that does not require their expertise.
The better question is not "can we automate this?" It is: "what kind of work is this, and what level of human involvement does it actually need?"
After working across hundreds of enterprise data programs, a clearer model has emerged. All data engineering work falls into three categories, each requiring a fundamentally different approach.

See How These Categories Play Out in Real Programs
For a look at how these categories play out in real modernization programs, see our analysis of why data modernization timelines slip.
Read the related → https://www.3xdataengineering.com/
Category 1: Work That Requires Human Judgment
Some data engineering decisions cannot be delegated to AI because they require organizational context, risk tolerance, and the ability to navigate competing stakeholder priorities. These are the decisions where getting it wrong creates problems that take months to untangle. They sit at the intersection of technology and organizational strategy, and they account for the most consequential choices in any data modernization program.
Architecture and platform decisions
Choosing between Snowflake and Databricks for a specific workload is not a pattern-matching exercise. It requires understanding the organization's existing skill sets, vendor relationships, cost structure, governance requirements, and three-year data strategy. An AI can surface comparison data, but the decision itself depends on judgment that accounts for factors no model has access to.
Business logic interpretation
Legacy systems contain business rules embedded in stored procedures, ETL logic, and scheduling dependencies that were never formally documented. Deciding what a piece of logic actually means, whether it is still relevant, whether it should be preserved or redesigned during migration, requires someone who understands the business context, not just the code syntax.
Trade-off analysis and program prioritization
Which workloads migrate first? Where do you accept technical debt versus investing in clean redesign? How do you balance speed against long-term maintainability? These are judgment calls that depend on organizational priorities, stakeholder dynamics, and risk appetite. No framework or AI tool can make them reliably.
Category 2: Work That AI Can Accelerate
This is the category most teams get wrong. Acceleration means AI provides a strong, domain-aware starting point that experienced engineers review, refine, and approve. The human is still in the loop, but instead of starting from a blank page, they start from 80% done. That distinction matters. Teams that try to fully automate Category 2 work end up with outputs nobody trusts. Teams that handle it fully manually waste their best engineers on work that AI could have drafted for them.

Legacy system reverse engineering
Understanding what a legacy codebase actually does used to require months of manual discovery: tracing data flows, mapping dependencies, piecing together transformation logic from undocumented stored procedures. AI-powered reverse engineering can now ingest an entire codebase, trace those same logic flows, and generate documentation in days. Engineers still review and validate the output. But they are reviewing a complete analysis rather than building one from scratch, and that changes the timeline for the entire program.
Solution architecture and data model design
AI accelerators can generate solution architecture blueprints and data model designs from analyzed source systems, using target platform best practices as constraints. The output is not a finished design, and it should not be treated as one. It is a well-informed starting point that an architect evaluates against organizational requirements, modifies where needed, and approves. What changes is the starting line, not the accountability.
Fact-based estimation and roadmapping
Instead of applying generic multipliers to object counts, AI-powered estimation engines assess each object's actual complexity, transformation patterns, and downstream impact. The output is a defensible, SI-grade roadmap that a program manager reviews and adjusts. The estimation phase drops from 6-12 weeks to 3-5 days, and the estimate is grounded in system facts rather than assumptions.
Explore 3XDE's AI-Powered Accelerators
Learn more about how 3XDE's AI-powered accelerators handle legacy reverse engineering, architecture design, and fact-based estimation.
See the Accelerators → https://www.3xdataengineering.com/accelerators
Category 3: Work That Should Be Fully Automated
The third category is work that follows clear, repeatable patterns. No judgment is required. No ambiguity in the inputs. The rules are well-defined and the output can be validated deterministically. This work should be fully automated, not because it is easy, but because it is predictable. And predictable work, done manually at enterprise scale, is what creates the delivery bottleneck that derails program timelines.
Bulk code conversion across platforms
Converting SQL dialects, ETL job syntax, and stored procedure logic from one platform to another (Oracle to Snowflake, Teradata to Databricks) follows well-defined transformation rules. When a team is facing 5,000 SQL scripts and 800 ETL jobs, manual conversion creates a bottleneck that no staffing plan can solve. Purpose-built AI accelerators handle these conversions at scale with semantic accuracy and consistency controls. Human engineers no longer translate individual scripts. They validate the automated output and focus their expertise on the edge cases that require contextual understanding.
Metadata extraction and cataloging
Scanning data assets, extracting schema information, profiling data quality, and generating catalog entries is mechanical work that AI handles faster and more consistently than manual effort. Automated metadata intelligence surfaces what exists, how it connects, and where the gaps are, without engineers spending weeks inventorying systems by hand.
Pipeline scaffolding and test generation
Generating boilerplate pipeline code, data quality test suites, and monitoring configurations from defined patterns is automation territory. The patterns are well-understood, the inputs are structured, and the outputs can be validated against clear acceptance criteria.
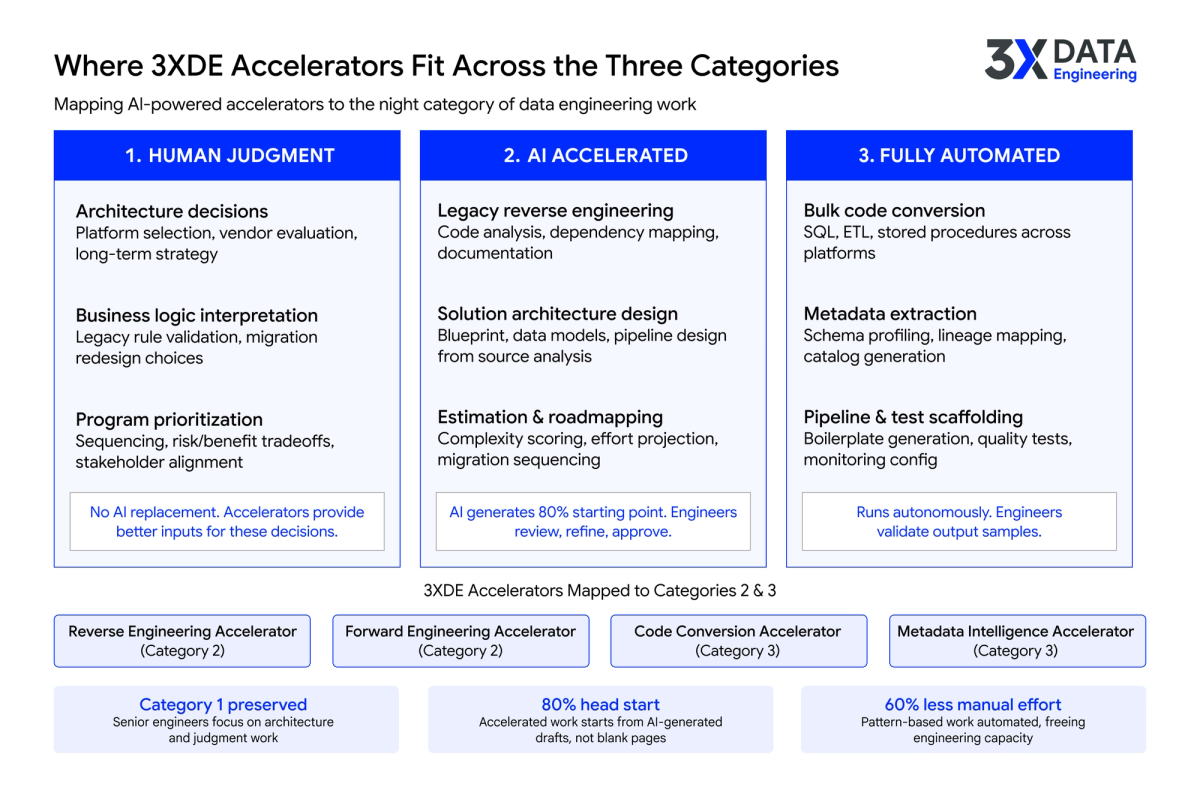
How 3X Data Engineering Approaches This
3X Data Engineering's accelerator suite maps directly to this three-category model. For Category 2 work, the Reverse Engineering and Forward Engineering Accelerators provide domain-aware starting points for legacy analysis, solution architecture, and data model design. Engineers review and approve the output. For Category 3, the Code Conversion and Metadata Intelligence Accelerators fully automate the pattern-based work that consumes the most hours: bulk SQL conversion, schema extraction, documentation generation.
The outcome is not fewer engineers. It is engineers spending their time where it counts. Architecture decisions, business logic interpretation, trade-off analysis, the work in Category 1 where their judgment is irreplaceable. The accelerators handle the volume. The engineers handle the decisions.
Classify Your Workload with 3XDE's Acceleration Advisory
If your team is evaluating where automation fits in your data engineering function, 3XDE's Acceleration Advisory can help you classify your workload and build a practical automation roadmap.
Talk to an Advisor → https://www.3xdataengineering.com/advisory
Looking Ahead
The data engineering teams that perform best over the next two years will not be the ones that automated the most or the least. They will be the ones that got the classification right, that built clear categories for their work, matched each category to the right level of human involvement, and continuously re-evaluated as AI capabilities improved. The framework is simple. The discipline to apply it consistently is what separates teams that deliver from teams that are still debating where to start.

