AI-Augmented Legacy Code Modernization: A Four-Stage Framework
Key takeaways
- Most legacy modernization programs stall in inventory and complexity scoring, not in conversion.
- Object-level complexity scoring is the difference between a defensible plan and a spreadsheet estimate.
- AI handles the volume. Engineers handle the design decisions. The split is what makes the timelines work.
- Realistic outcomes per stage: inventory in days, scoring in days, conversion in weeks, validation in days per wave.

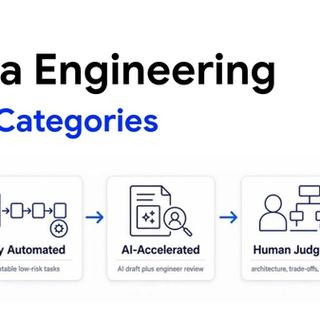
Stage 1: Inventory
Source-connected inventory is the foundation. Connect read-only to the source system. Extract every database object: tables, stored procedures, views, functions, triggers, indexes, security objects, and pipeline definitions. Build a complete dependency graph. Document data volumes and query patterns observed in the live system.
What changes with AI acceleration. Inventory work that traditionally takes four to six weeks of analyst time compresses to two to five days of accelerator runtime. The output is broader (more objects discovered) and more accurate (no manual cataloging errors) than manual approaches. The output is also reproducible: a re-run produces a schema diff, not a fresh inventory.
Realistic outcome: complete inventory of mid-size estates in two to three business days. Larger estates run three to five business days.
Stage 2: Complexity scoring
Every object is scored individually for migration complexity. Lines of code, dependency depth, language construct complexity, target platform compatibility gaps, and migration risk. Each object gets a tier: standard, complex, architect-required. The scoring is the input to accurate effort estimation.
Why this matters. Estimation built on average-time-per-object carries a 40 to 60 percent error margin. Estimation built on per-object complexity scoring carries a 10 to 15 percent margin. The accuracy difference compounds across hundreds or thousands of objects.
Realistic outcome: complexity scoring across a 500 to 1,500 object estate in two to four business days.

Stage 3: Conversion
Standard-tier objects convert automatically through accelerators. Complex-tier objects are converted with engineer review. Architect-required objects are routed to senior engineers with context already attached. The split is what makes the timeline work.
What does not change with AI. Architecture decisions still require senior judgment. Performance tuning still requires engineering review. Edge cases still require human attention. AI handles the 60 to 75 percent of conversion work that follows recognizable patterns. The remainder is where engineers spend their time.
Realistic outcome: conversion of a mid-size estate (500 to 1,500 objects) in six to twelve weeks of execution, depending on language family and complexity profile.

Stage 4: Validation
Automated reconciliation compares source and target outputs across migrated objects. Row-level comparison, aggregate comparison, statistical comparison. Discrepancies are flagged for engineering review before sign-off on each migration wave. Validation is not a separate phase. It is built into each migration wave.
Why automated reconciliation beats sample-based testing. Sample testing misses pattern-level issues that show up across many objects. Automated reconciliation surfaces issues at scale. The investment in validation tooling pays back across every migration wave.
Realistic outcome: validation per wave in one to two business days, not weeks of manual testing.
Where teams underestimate
- Inventory takes longer than expected without source-connected discovery
- Complexity scoring is skipped, leading to estimation errors that surface in week eight
- Conversion is treated as the bottleneck when assessment is the actual bottleneck
- Validation is left to the end and becomes a discovery exercise about how broken the conversion is.
Plan your modernization with a fact-based blueprint
If you are working on legacy code modernization, the next practical step is a fixed-price Modernization Assessment. Source-connected discovery, complexity scoring, target architecture, effort estimation, and bulk-converted sample code, delivered as a Modernization Canvas in 8 business days. No long discovery, no procurement cycle, Director-level signing authority.